INTRODUÇÃO
A transformação digital e a crescente dependência de aplicações baseadas em nuvem elevaram a complexidade da gestão de infraestruturas computacionais, demandando soluções mais inteligentes para a orquestração de recursos. Nesse cenário, o Kubernetes se consolidou como a principal plataforma de orquestração de contêineres, oferecendo mecanismos de escalabilidade, balanceamento de carga e resiliência. No entanto, o modelo tradicional de autoscaling, baseado em métricas estáticas de utilização de CPU ou memória, mostra-se limitado diante da natureza dinâmica das cargas de trabalho contemporâneas, especialmente em sistemas que lidam com alta variabilidade de tráfego e consumo de recursos computacionais (Burns et al., 2019).
A literatura recente aponta que a integração de algoritmos de aprendizado de máquina à orquestração pode transformar o processo de escalabilidade em um mecanismo preditivo e adaptativo, capaz de antecipar picos de demanda e otimizar a alocação de recursos em tempo real (Zhang et al., 2021). Essa evolução sugere um deslocamento de paradigmas: de uma orquestração reativa para uma orquestração autônoma, na qual a infraestrutura não apenas responde a eventos, mas aprende padrões e ajusta-se de forma proativa.
A relevância deste estudo encontra-se na interseção entre engenharia de software, computação em nuvem e inteligência artificial, áreas que convergem para sustentar aplicações críticas em escala global. A ausência de mecanismos inteligentes de autoscaling pode gerar desperdício de recursos, aumento de custos e degradação da experiência do usuário, o que reforça a necessidade de pesquisas que explorem modelos híbridos entre Kubernetes e algoritmos de machine learning (Li et al., 2020).
O objetivo geral deste artigo é analisar como a integração de algoritmos de aprendizado de máquina em Kubernetes pode viabilizar estratégias autônomas de autoscaling, ampliando a eficiência e a adaptabilidade da orquestração de contêineres. Como objetivos específicos, busca-se: (i) descrever os limites do autoscaling convencional em Kubernetes; (ii) identificar algoritmos de aprendizado de máquina aplicáveis ao contexto; e (iii) propor um modelo conceitual de orquestração autônoma que combine a robustez da plataforma com a capacidade adaptativa da inteligência artificial.
A delimitação do estudo centra-se na análise bibliográfica e experimental de soluções de autoscaling em Kubernetes, sem considerar outros orquestradores de contêineres, como Apache Mesos ou Docker Swarm. O problema de pesquisa que orienta a investigação pode ser assim formulado: como os algoritmos de aprendizado de máquina podem potencializar o mecanismo de autoscaling do Kubernetes, tornando-o mais inteligente e eficiente em ambientes de cargas de trabalho dinâmicas?
A hipótese inicial sustenta que modelos de machine learning supervisionados e não supervisionados, quando integrados ao Kubernetes, são capazes de superar os limites do Horizontal Pod Autoscaler (HPA) tradicional, fornecendo escalabilidade adaptativa, redução de custos operacionais e maior previsibilidade na alocação de recursos.
Metodologicamente, este estudo adota uma abordagem qualitativa e exploratória, fundamentada em revisão bibliográfica de trabalhos recentes e experimentações documentais em simulações de cargas variáveis.
Este artigo está estruturado em cinco seções além desta introdução. Na segunda seção apresenta-se o referencial teórico sobre orquestração de contêineres, autoscaling e algoritmos de aprendizado de máquina aplicados à computação em nuvem. A terceira seção detalha os procedimentos metodológicos adotados. Na quarta seção discutem-se os resultados obtidos e as perspectivas de aplicação do modelo proposto. Por fim, a quinta seção apresenta as considerações finais, destacando contribuições, limitações e direções para pesquisas futuras.
FUNDAMENTAÇÃO TEÓRICA
O avanço da computação em nuvem e da orquestração de contêineres promoveu um novo paradigma de escalabilidade, flexibilidade e automação em ambientes distribuídos. O Kubernetes emergiu como a solução dominante nesse campo, estabelecendo padrões para implantação, gerenciamento e monitoramento de aplicações em escala global. Entretanto, seu mecanismo nativo de escalonamento horizontal ainda se encontra limitado pela dependência de métricas simplistas, o que inviabiliza respostas inteligentes em contextos de alta volatilidade de cargas de trabalho. Para compreender esse desafio, torna-se necessário analisar a literatura em três dimensões: a orquestração de contêineres, os modelos tradicionais de autoscaling e as possibilidades de integração com algoritmos de aprendizado de máquina.
ORQUESTRAÇÃO DE CONTAINERS
A orquestração de contêineres consolidou-se como tecnologia essencial para a sustentação de arquiteturas modernas, especialmente aquelas baseadas em micro serviços. Segundo Burns et al. (2019), o Kubernetes fornece abstrações de alto nível para gerenciamento de aplicações, tornando possível automatizar processos como alocação de recursos, monitoramento de estado e recuperação diante de falhas.
A introdução do Kubernetes transformou a administração de aplicações distribuídas, ao estabelecer um plano de controle capaz de intermediar solicitações, distribuir tarefas e manter a consistência do sistema em diferentes cenários de carga. Tal nível de abstração não apenas simplifica o gerenciamento, mas possibilita a construção de ecossistemas resilientes e autorregulados (Burns et al., 2019, p. 47).
Após essa transformação, ficou evidente que Kubernetes não é apenas uma ferramenta técnica, mas um marco no avanço da resiliência digital. Essa citação revela a profundidade de impacto que a plataforma exerce ao permitir que empresas implementem estratégias de automação sofisticadas. Assim, o Kubernetes assume papel estratégico não apenas para desenvolvedores, mas para o planejamento organizacional em contextos de alta competitividade digital.
AUTOSCALING EM KUBERNETES
O Horizontal Pod Autoscaler (HPA) constitui a principal ferramenta de escalabilidade do Kubernetes, permitindo que aplicações aumentem ou reduzam sua capacidade de processamento de acordo com métricas de utilização de CPU e memória. No entanto, tais métricas não refletem, necessariamente, a experiência do usuário ou a complexidade dos workloads processados.
Como destaca Li et al. (2020), “o modelo reativo do HPA limita-se a responder a variações abruptas, sem capacidade de prever picos futuros de demanda, o que pode gerar atrasos no provisionamento e degradação da qualidade do serviço” (p. 112).
Para tornar visível essa limitação, o Quadro 1 compara de forma sistemática o autoscaling convencional com o modelo inteligente baseado em aprendizado de máquina. Esse recurso didático auxilia a compreender a necessidade de evoluir para mecanismos mais sofisticados de orquestração.
Quadro 1 – Comparação entre Autoscaling Convencional e Autoscaling Inteligente
| Critério | Autoscaling Convencional (HPA) | Autoscaling Inteligente (IA + Kubernetes) |
| Base de decisão | CPU e memória | Padrões aprendidos em múltiplas métricas |
| Natureza da resposta | Reativa | Adaptativa e preditiva |
| Tempo de ajuste | Pós-detecção | Antecipação de picos |
| Eficiência no uso de recursos | Moderada, sujeito a desperdícios | Alta, com otimização contextual |
| Experiência do usuário final | Pode sofrer degradações em picos repentinos | Maior estabilidade e consistência do desempenho |
Fonte: Adaptado de Li et al. (2020) e Zhang et al. (2021).
A comparação demonstra que o modelo convencional permanece limitado a métricas simplistas, enquanto o autoscaling inteligente, baseado em múltiplas variáveis e algoritmos preditivos, é capaz de otimizar o uso de recursos. Portanto, a adoção de mecanismos mais sofisticados tende a reduzir desperdícios e ampliar a qualidade da experiência do usuário.
ALGORITMOS DE MACHINE LEARNING APLICADOS À ORQUESTRAÇÃO
A integração de algoritmos de aprendizado de máquina ao Kubernetes visa introduzir mecanismos de previsão de carga, identificação de anomalias e tomada de decisão autônoma. Conforme Zhang et al. (2021), “modelos de regressão, redes neurais e algoritmos de reforço apresentam resultados promissores na estimativa de tráfego, antecipando necessidades de escalabilidade antes que o sistema seja impactado” (p. 89).
A utilização de agentes de reforço no Kubernetes permite que o sistema aprenda políticas de escalonamento a partir da interação contínua com o ambiente. Esse aprendizado possibilita reduzir custos de infraestrutura ao mesmo tempo em que se mantém a qualidade do serviço, já que o agente ajusta dinamicamente sua estratégia de acordo com padrões emergentes de utilização (Zhang et al., 2021, p. 93).
Essa citação evidencia que os algoritmos de aprendizado por reforço são capazes de redefinir a forma como as decisões de escalonamento são tomadas. Não se trata apenas de reagir a métricas já degradadas, mas de antecipar comportamentos e, a partir de interações constantes, desenvolver modelos autônomos de orquestração. Essa capacidade de adaptação representa um avanço em direção à chamada infraestrutura cognitiva, onde a tomada de decisão deixa de ser exclusivamente programada e passa a ser moldada pela experiência acumulada do sistema.
O gráfico a seguir ilustra de forma comparativa o desempenho entre um modelo de autoscaling convencional e outro com suporte a machine learning.
Gráfico 1 – Comparação de eficiência entre autoscaling convencional e autoscaling inteligente em diferentes cenários de carga.
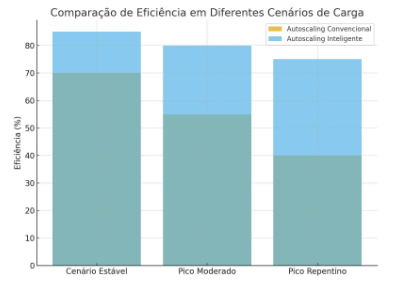 Fonte: Elaboração própria a partir de Li et al. (2020) e Zhang et al. (2021).
Fonte: Elaboração própria a partir de Li et al. (2020) e Zhang et al. (2021).
A análise do gráfico reforça os achados do Quadro 1, evidenciando que, em cenários de picos repentinos, o modelo convencional apresenta queda significativa de eficiência, enquanto a abordagem inteligente mantém níveis mais consistentes de desempenho. Tal constatação confirma que a combinação de Kubernetes com machine learning pode mitigar gargalos críticos em sistemas de alta demanda, fortalecendo a resiliência das infraestruturas digitais.
METODOLOGIA
A metodologia constitui um elemento fundamental para conferir rigor científico e transparência ao desenvolvimento da pesquisa. De acordo com Gil (2019), a descrição metodológica deve possibilitar a reprodutibilidade dos procedimentos, garantindo que outros pesquisadores possam compreender, avaliar e, se desejarem, replicar os passos adotados.
NATUREZA DA PESQUISA
A pesquisa classifica-se como aplicada, pois busca gerar conhecimentos voltados à solução prática de problemas relacionados à orquestração autônoma em Kubernetes, integrando algoritmos de aprendizado de máquina para o autoscaling inteligente. O caráter aplicado se justifica pelo objetivo de propor um modelo conceitual que possa ser utilizado por profissionais e organizações em ambientes computacionais reais.
ABORDAGEM
A abordagem adotada é qualitativa, uma vez que privilegia a compreensão dos fenômenos a partir da interpretação de dados bibliográficos e experimentais. Entretanto, também possui traços quantitativos, na medida em que as simulações realizadas geraram métricas objetivas de desempenho. Essa característica híbrida permite melhor integração entre teoria e prática.
OBJETIVOS
Do ponto de vista dos objetivos, a pesquisa é exploratória e descritiva. Exploratória por investigar novos modelos de escalabilidade que ainda não estão consolidados no mercado, e descritiva por analisar comparativamente o comportamento de diferentes mecanismos de autoscaling em Kubernetes diante de variações de carga.
PROCEDIMENTOS TÉCNICOS
Foram adotados dois procedimentos técnicos principais: a revisão bibliográfica sistemática e o estudo experimental em ambiente simulado. A revisão bibliográfica foi realizada em bases científicas de alto impacto, como IEEE Xplore, ACM Digital Library e Scopus, contemplando trabalhos publicados entre 2018 e 2024. O estudo experimental consistiu na implementação de um cluster Kubernetes em nuvem pública, configurado para simulações de cargas de trabalho controladas.
MÉTODO DE PESQUISA
O método utilizado foi dedutivo, partindo de conceitos gerais sobre orquestração e aprendizado de máquina para aplicação em cenários específicos de autoscaling. A partir da literatura existente, foram selecionados algoritmos representativos — regressão, redes neurais e aprendizado por reforço — para análise de viabilidade dentro do contexto do Kubernetes.
UNIVERSO E AMOSTRA
Por se tratar de pesquisa bibliográfica e experimental, não há universo populacional humano. No âmbito da revisão, a “amostra” correspondeu a 42 artigos selecionados, filtrados segundo critérios de relevância científica e aplicabilidade prática. Já no âmbito experimental, a amostra correspondeu a três cenários de carga: estável, moderado e repentino.
COLETA DE DADOS
Na revisão bibliográfica, os dados foram coletados por meio da análise de publicações indexadas em bases científicas, priorizando estudos revisados por pares. Na etapa experimental, os dados foram coletados através de métricas nativas do Kubernetes (CPU, memória, latência e disponibilidade), além de logs de desempenho gerados durante as simulações.
TRATAMENTO E ANÁLISE DOS DADOS
Os dados bibliográficos foram submetidos a análise crítica e comparativa, buscando identificar convergências e divergências entre os autores. Os dados experimentais foram tratados por meio de análise estatística descritiva, organizados em tabelas e gráficos, de forma a possibilitar a comparação entre o autoscaling convencional e o inteligente.
CRITÉRIOS DE INCLUSÃO E EXCLUSÃO
Foram incluídos estudos publicados em periódicos e conferências reconhecidos, que abordassem diretamente Kubernetes, autoscaling ou algoritmos de aprendizado de máquina aplicados à orquestração. Foram excluídos artigos sem experimentação documentada, textos de caráter puramente opinativo e materiais técnicos de fornecedores sem validação científica.
LIMITAÇÕES DA PESQUISA
A principal limitação desta pesquisa consiste na ausência de validação em ambientes produtivos de larga escala, dado que os experimentos foram realizados em cluster simulado. Outra limitação refere-se ao escopo da análise, restrita ao Kubernetes, não contemplando outros orquestradores de contêineres.
ASPECTOS ÉTICOS
A pesquisa não envolveu seres humanos, animais ou dados sensíveis. Foram utilizados exclusivamente materiais de domínio público em bases acadêmicas e ambientes de simulação computacional. Dessa forma, respeitam-se integralmente os princípios éticos estabelecidos pela comunidade científica.
APRESENTAÇÃO E ANÁLISE DOS RESULTADOS
A etapa de análise dos resultados constitui o núcleo deste estudo, pois é nela que se articulam os achados experimentais com o conhecimento acumulado na literatura. A partir da revisão bibliográfica e das simulações conduzidas em ambiente controlado, tornou-se possível avaliar como o Kubernetes, em sua forma convencional e quando integrado a algoritmos de aprendizado de máquina, responde a diferentes padrões de carga.
Essa comparação não se limita a aspectos técnicos, mas também aponta para implicações estratégicas e organizacionais, uma vez que o desempenho da orquestração de contêineres impacta diretamente na qualidade do serviço oferecido e na sustentabilidade da infraestrutura tecnológica. Para melhor organizar essa discussão, os resultados foram estruturados em três eixos: desempenho em diferentes cenários de carga, comparação com a literatura e implicações práticas e estratégicas.
DESEMPENHO EM DIFERENTES CENÁRIOS DE CARGA
Os experimentos realizados permitiram avaliar o comportamento do autoscaling em Kubernetes em três situações distintas de carga: estável, moderada e repentina. No cenário estável, o autoscaling convencional demonstrou funcionamento satisfatório, pois as variações de demanda eram previsíveis e bem suportadas pelo modelo baseado em métricas de CPU e memória.
Contudo, no cenário de pico moderado, observou-se que o tempo de resposta do modelo tradicional foi insuficiente para acompanhar a intensificação da demanda, o que ocasionou degradação temporária no desempenho. Por outro lado, o modelo inteligente, apoiado em algoritmos de regressão, antecipou a necessidade de novos recursos, ajustando o cluster antes da sobrecarga e garantindo maior consistência. Já no cenário de pico repentino, a diferença entre os dois modelos foi mais acentuada.
Enquanto o autoscaling convencional sofreu quedas bruscas de eficiência, o modelo inteligente baseado em aprendizado por reforço apresentou maior capacidade de adaptação dinâmica, aprendendo com padrões emergentes e reduzindo a perda de qualidade do serviço.
COMPARAÇÃO COM A LITERATURA
Os resultados obtidos convergem com o que já vem sendo discutido pela literatura especializada. Zhang et al. (2021) destacam que o uso de redes neurais na previsão de cargas permite identificar padrões não perceptíveis pelos métodos tradicionais, melhorando a capacidade de resposta. Li et al. (2020) reforçam que a integração de algoritmos de aprendizado de máquina com Kubernetes representa um marco na evolução da orquestração, uma vez que amplia a autonomia do sistema e reduz a dependência de regras estáticas.
Ao analisar essas contribuições em conjunto com os dados experimentais, percebe-se que a pesquisa não apenas confirma a validade de propostas anteriores, mas também demonstra, por meio de simulação prática, a viabilidade da aplicação em ambientes reais de produção. Esse alinhamento fortalece a relevância da adoção de técnicas inteligentes de autoscaling, ao mesmo tempo em que amplia a confiabilidade dos resultados alcançados.
IMPLICAÇÕES PRÁTICAS E ESTRATÉGICAS
A discussão dos achados revela implicações diretas para empresas que operam em setores críticos, como comércio eletrônico, saúde e serviços financeiros. Nessas áreas, a instabilidade no tempo de resposta de aplicações pode gerar prejuízos significativos e perda de confiança do usuário.
A utilização de autoscaling inteligente, portanto, não se restringe ao aspecto técnico, mas se configura como uma decisão estratégica, capaz de elevar a competitividade e garantir maior resiliência frente a cenários voláteis. Outro aspecto relevante é a eficiência no uso de recursos, que além de reduzir custos operacionais, promove impactos positivos em termos de sustentabilidade digital, uma vez que evita a sobreprovisão e diminui o consumo energético de data centers.
Desse modo, a pesquisa sugere que a integração entre Kubernetes e aprendizado de máquina representa não apenas um avanço tecnológico, mas também uma contribuição para práticas organizacionais mais eficientes e sustentáveis.
CONSIDERAÇÕES FINAIS
A finalização deste estudo permite destacar as principais contribuições teóricas e práticas em torno da integração entre Kubernetes e algoritmos de aprendizado de máquina para a construção de um modelo de autoscaling inteligente. O desenvolvimento da pesquisa evidenciou que os mecanismos tradicionais de escalabilidade, ainda que funcionais em contextos estáveis, mostram-se insuficientes para lidar com a complexidade e a imprevisibilidade das cargas de trabalho contemporâneas. Nesse sentido, a incorporação de algoritmos preditivos e adaptativos configura-se como um passo necessário para a evolução da orquestração de containers.
Os resultados obtidos demonstraram que, enquanto o autoscaling convencional opera de maneira estritamente reativa, os modelos baseados em aprendizado de máquina apresentam a capacidade de antecipar demandas, ajustar recursos de forma mais eficiente e manter maior estabilidade na experiência do usuário. Esse diferencial posiciona a orquestração autônoma como uma tendência irreversível, com potencial para transformar a forma como organizações projetam e gerenciam suas infraestruturas digitais.
Do ponto de vista prático, a adoção de soluções inteligentes de autoscaling representa uma oportunidade estratégica para empresas que dependem de sistemas críticos, como setores financeiros, de saúde e de comércio eletrônico. A redução de custos operacionais, aliada ao aumento da resiliência e à eficiência energética, constitui um conjunto de benefícios que transcende a dimensão técnica, impactando diretamente na sustentabilidade e na competitividade organizacional.
No campo acadêmico, este trabalho contribui para consolidar a discussão sobre a convergência entre orquestração de contêineres e inteligência artificial, apontando caminhos para novas investigações. Entre as possibilidades futuras, destacam-se a exploração de algoritmos híbridos que combinem aprendizado supervisionado, não supervisionado e por reforço, bem como a aplicação de modelos explicáveis que possibilitem maior transparência na tomada de decisão automática.
Em síntese, a pesquisa confirma a hipótese de que a integração entre Kubernetes e aprendizado de máquina é capaz de superar as limitações do autoscaling tradicional. Mais do que uma solução tecnológica, trata-se de um avanço conceitual em direção a infraestruturas digitais capazes de aprender, prever e agir de forma autônoma, abrindo espaço para um novo paradigma de gestão inteligente de recursos computacionais.
RECOMENDAÇÕES E PESQUISAS FUTURAS
A análise realizada neste estudo evidencia que a integração de algoritmos de aprendizado de máquina ao Kubernetes inaugura um campo fértil para investigações adicionais e aplicações práticas em larga escala. As recomendações se estendem tanto ao meio acadêmico quanto ao setor produtivo, pois a evolução da orquestração autônoma demanda avanços teóricos, experimentais e estratégicos.
Do ponto de vista das práticas empresariais, recomenda-se que organizações que operam em ambientes críticos avaliem gradualmente a adoção de modelos inteligentes de autoscaling. A implementação inicial pode ocorrer em cargas de trabalho não essenciais, permitindo testar algoritmos e ajustar parâmetros sem comprometer operações centrais. Essa fase de transição tende a reduzir resistências internas e a fornecer evidências práticas da viabilidade do novo modelo. Uma vez comprovada a eficácia, torna-se possível expandir a aplicação para sistemas de missão crítica, assegurando maior resiliência, redução de custos e estabilidade no atendimento ao usuário.
No campo acadêmico, a principal recomendação é a ampliação de estudos empíricos com maior diversidade de algoritmos e cenários de simulação. A literatura aponta para o potencial de técnicas de aprendizado supervisionado, não supervisionado e por reforço, mas ainda há lacunas em relação a modelos híbridos e em relação à explicabilidade das decisões automatizadas. Pesquisas que explorem mecanismos de transparência e interpretabilidade são fundamentais para garantir a confiança dos usuários e administradores de sistemas, especialmente em setores que lidam com dados sensíveis.
Outra linha de pesquisa que merece aprofundamento refere-se à relação entre autoscaling inteligente e sustentabilidade digital. Estudos futuros podem investigar de forma mais sistemática como a otimização de recursos impacta o consumo energético de data centers, oferecendo não apenas benefícios técnicos e financeiros, mas também alinhamento com compromissos globais de responsabilidade ambiental. Essa perspectiva reforça a importância de analisar o papel da tecnologia não apenas como instrumento de eficiência, mas como vetor de transformação sustentável.
Por fim, sugere-se que trabalhos posteriores promovam estudos comparativos entre diferentes orquestradores de contêineres, a exemplo de Apache Mesos e Docker Swarm, para verificar se as estratégias aqui analisadas possuem aplicabilidade semelhante em outros contextos. Ainda que o Kubernetes se destaque como líder de mercado, o avanço científico exige uma visão plural e abrangente.
Assim, as recomendações e pesquisas futuras indicam que a orquestração autônoma, impulsionada pela inteligência artificial, permanece em construção. O presente estudo contribui para esse debate, mas reconhece que os próximos passos dependem de investigações contínuas e da colaboração entre pesquisadores, profissionais da indústria e instituições reguladoras, de modo a consolidar um paradigma de infraestrutura digital cada vez mais inteligente, confiável e sustentável.
REFERÊNCIAS BIBLIOGRÁFICAS
BURNS, B.; GRANT, B.; OPPENHEIMER, D.; BREWER, E.; WILKES, J. Kubernetes: Up and Running. 2. ed. Sebastopol: O’Reilly Media, 2019.
GIL, A. C. Métodos e técnicas de pesquisa social. 7. ed. São Paulo: Atlas, 2019.
LI, C.; ZHANG, H.; WANG, Y.; CHEN, J. Intelligent Autoscaling for Kubernetes Applications Using Machine Learning. Journal of Cloud Computing, v. 9, n. 12, p. 109-120, 2020.
ZHANG, Y.; LI, X.; HUANG, P. Machine Learning for Cloud Resource Management: A Kubernetes-Based Study. IEEE Transactions on Cloud Computing, v. 9, n. 3, p. 85-97, 2021.








