INTRODUÇÃO
O termo compressão sem perda de dados (do inglês lossless data compression) se refere a métodos de compressão de dados aplicados por algoritmos em que a informação obtida após a descompressão é idêntica à informação original (antes de ser comprimida), diferentemente da compressão com perda de dados.
Comprimir dados é o ato de reduzir o espaço ocupado por dados no determinado dispositivo digital, como um dispositivo computacional. Essa operação é realizada através de diversos algoritmos de compressão, reduzindo a quantidade de bytes (1 byte equivale a 8 bits) para representar um dado, podendo esse dado ser uma imagem, um texto, um vídeo, um áudio ou um arquivo qualquer.
Comprimir dados destina-se também a retirar a redundância, que caracteriza aquilo que é dito ou feito em excesso, tornando-se repetitivo. A redundância se refere a alguma situação em que as informações já tenham sido dadas e que novamente voltam a ser mencionadas em outro momento.
Muitos dados contêm informações redundantes que podem ou precisam ser eliminadas de alguma forma. Essa forma é através de uma regra, chamada de código ou protocolo, que, quando seguida, elimina os bits redundantes de informações, de modo a diminuir seu tamanho nos arquivos. Por exemplo, a sequência “BBBBBBBB“ que ocupa 8 bytes, poderia ser representada pela sequência “8B”, que ocupa 2 bytes, então o espaço usado seria dado pela fórmula (2 bytes usados em 8 bytes totais) * 100%, igualdade equivalente a 25% que foi utilizado e, economizando assim, 75% de espaço.
Além da eliminação da redundância, os dados são comprimidos por diversos motivos, por exemplo, economizar espaço em dispositivos de armazenamento (como discos rígidos ou pen drives) e diminuir o tempo em que acontecem as transmissões dos dados, ganhando desempenho.
Embora possam parecer sinônimos, compressão e compactação de dados são processos distintos. A compressão, como visto, reduz a quantidade de bits para representar algum dado, enquanto a compactação tem a função de unir dados que não estejam unidos. Um exemplo clássico de compactação de dados é a desfragmentação de discos.
Existem diversas formas de se classificar os métodos de compressão de dados. O mais conhecido é pela ocorrência ou não de perda de dados durante o processo. Entretanto diversas outras formas de classificação são úteis para se avaliar e comparar os métodos de compressão de dados, e sua aplicação em problemas específicos. SALOMON, D. de Data Compression. The Complete Reference 2 ed. Nova Iorque, 2000: Springer. ISBN 0-387-95045-1, p 7 – 8.
DEFINIÇÃO DE CODECS
Codecs (abreviação de codificador/decodificador) são programas utilizados para codificar e decodificar arquivos de mídia. Ou seja, eles compactam o formato original, favorecendo o armazenamento, e descompactam na hora da reprodução, transformando novamente em dados como vídeo, imagem ou áudio.
Em caso de compactação, há dois tipos de codec: sem perda e com perda. O primeiro tipo não altera os dados. Já o segundo codifica dados com perda de qualidade, objetivando alcançar taxas de conversão mais elevadas.
Os codecs podem ser encontrados na forma de programas para serem instalados no sistema operacional do computador ou programas embutidos em equipamentos, como reprodutores de CD, DVD ou Blue Ray.
Atualmente, há codecs sem perdas para diversos formatos que serão demonstrados posteriormente alguns exemplos. Com tamanha diversidade de formatos, é importante verificar no momento da compra de um equipamento se ele suporta os formatos mais atuais, pois normalmente não é possível fazer a instalação de um codec no aparelho.
Para os usuários de computadores, é necessário apenas instalar o codec, algo que se tornou muito fácil com a criação dos chamados pacotes de codecs, programas que agrupam diversos codecs em um instalador. Além desses pacotes, existem programas de reprodução que suportam qualquer formato sem exigir que outros sejam instalados.
Normalmente só descobrimos a importância de um codec quando é preciso assistir a um filme e o player não consegue reproduzi-lo. Mas a verdade é que, sem o uso de codec, os arquivos multimídia seriam enormes e seu transporte em mídias removíveis ou pela Internet, impraticáveis. Também não seria possível usar sistemas de proteção, o que inviabilizaria a comercialização de conteúdo com controle de direitos autorais.
CONCEITO DE ALGORITMOS E APLICAÇÃO NA COMPRESSÃO
Algoritmo é um conceito muito importante para a programação, pois todas as máquinas e programas de computador funcionam a partir de sequências de ações finitas que levam à realização de uma tarefa.
O papel do programador é pensar em todas as etapas das tarefas e descrevê-las de maneira objetiva e clara para que o computador possa realizá-las.
Um exemplo seria um programa que mostra se um aluno foi aprovado ou não em determinada disciplina. Considerando que a nota final seja a média das duas provas realizadas no semestre, os comandos seriam:
No entanto, os computadores não entendem a linguagem escrita dessa maneira, por isso os programadores devem “traduzir” esses comandos para linguagens de programação. Alguns exemplos de linguagem de programação são Java, Linguagem C, Linguagem C++, Linguagem C# e Python.
As operações de um algoritmo são realizadas de maneira muito rápida pelas máquinas. Um notebook comum, por exemplo, costuma fazer mais de um bilhão de operações por segundo.
Essa velocidade de operação revolucionou o mundo computacional, pois as máquinas podem fazer em pouquíssimo tempo cálculos que o ser humano levaria dias, meses ou até mesmo anos para realizar.
O mundo digital de hoje conecta todos que usam dispositivos portáteis, como PCs, telefones celulares e tablets. Isso também levou a um aumento no compartilhamento de dados que requer um gerenciamento de armazenamento em disco eficiente. Além disso, o compartilhamento de dados rápido e eficaz pela Internet exige que os tamanhos dos arquivos sejam o menor possível. Formatos de arquivo de compressão possuem algoritmos de compressão sem ou com perdas para comprimir dados. Isso ajuda a reduzir a utilização de armazenamento de disco e a transferência rápida de dados pela Internet.
ALGORITMOS DE COMPRESSÃO SEM PERDAS
Os algoritmos de compactação sem perdas pertencem a uma categoria de algoritmos de compactação de dados que comprimem os arquivos sem perder nenhum conteúdo. Isso significa que os algoritmos de compactação sem perdas podem reconstruir com precisão os dados originais dos dados compactados. Diversos algoritmos diferentes são projetados com um modelo típico de dados de entrada em mente ou assumindo que tipos de redundância os dados não compactados provavelmente conterão. A seguir, será apresentada uma breve explicação de alguns dos algoritmos de compressão sem perdas mais usados e um exemplo de funcionamento no qual o modelo foi utilizado.
CODIFICAÇÃO DE COMPRIMENTO DE EXECUÇÃO (RLE)
O RLE (Run Lenght Encoding) compacta dados substituindo sequências do mesmo valor por um único valor e uma contagem. Isso é especialmente eficaz para dados com muitos elementos repetidos.
Um exemplo é se uma imagem tiver uma linha de 15 pixels pretos seguidos por 5 pixels brancos (PPPPPPPPPPPPPPPBBBBB), o RLE poderá armazená-la como “15P, 5B”. Outro exemplo é uma sequência de 7 pixels brancos, 1 pixel preto, 12 pixels branco e 3 pixels pretos (BBBBBBBPBBBBBBBBBBBBPPP), o RLE poderá armazená-la como “7B,1P,12B,3P”.
O RLE é frequentemente usado em formatos de imagem simples, como BMP, e em aparelhos de fax para compactar imagens em preto e branco.
LEMPEL-ZIV-WELCH (LZW)
A compactação LZW recebeu o nome de seus desenvolvedores, A. Lempel e J. Ziv, com modificações posteriores de Terry A. Welch. É a principal técnica para compactação de dados de uso geral devido à sua simplicidade e versatilidade. Normalmente, você pode esperar que o LZW compacte texto, código executável e arquivos de dados semelhantes para cerca de metade do tamanho original. O LZW também tem um bom desempenho quando apresentado a arquivos de dados extremamente redundantes, como números tabulados, código-fonte do computador e sinais adquiridos. Taxas de compressão de 5:1 são comuns para esses casos. O LZW é a base de vários utilitários de computador pessoal que afirmam “dobrar a capacidade do seu disco rígido”. Essa compactação é sempre usada em arquivos de imagem GIF e oferecida como uma opção em TIFF e PostScript. A compressão LZW é protegida pela patente dos EUA número 4.558.302, concedida em 10 de dezembro de 1985 à Sperry Corporation (agora Unisys Corporation). As informações sobre licenciamento comercial são fornecidas pelo Departamento de Licenciamento Welch, Departamento Jurídico, M / SC2.
Esse modelo de compactação é usado em imagens GIF e formatos de compactação de arquivos mais antigos, como compactação TIFF e UNIX.
A compactação LZW cria um dicionário de padrões ou sequências à medida que processa os dados. Quando encontra uma sequência repetida, ele a substitui por um código mais curto que se refere à entrada do dicionário. O algoritmo LZW visa eliminar a necessidade de se emitir um caractere literal junto com o endereço do dicionário. Para isso, o dicionário é inicializado com todos os símbolos do alfabeto (ao se usar codificação ASCII, são 256 símbolos, de 0 a 255).
Abaixo são mostrados os passos do algoritmo usado para a codificação e decodificação (LZW). As convenções adotadas são:
Tabela com códigos e dicionários correspondentes
Fonte: PORTAL Unicamp – Filho, Danilo Zanatta – Algoritmo LZW (Lempel-Ziv-W). Disponível em https://www.decom.fee.unicamp.br/dspcom/EE088/Algoritmo_LZW.docvacidade. Acessado em 02 mai 2025
Figura 1 – Imagem do processo de codificação e decodificação

Fonte: PORTAL Unicamp – Filho, Danilo Zanatta – Algoritmo LZW (Lempel-Ziv-W). Disponível em https://www.decom.fee.unicamp.br/dspcom/EE088/Algoritmo_LZW.docvacidade. Acessado em 02 mai 2025

Conforme passado no algoritmo acima, a compressão LZW pode substituir cada repetição por um código que aponta para a primeira ocorrência no dicionário.
Segue um exemplo para melhor compreensão desse modelo de compressão, tomando como exemplo a sequência ABABBABAA, ajustada conforme a tabela abaixo.

Fonte: de autoria própria
Seguindo-se o algoritmo de codificação e chamando SC a sequência codificada, temos:
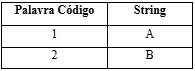
Fonte: de autoria própria

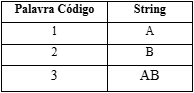
Fonte: de autoria própria

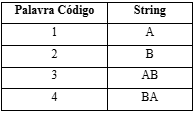
Fonte: de autoria própria

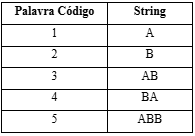
Fonte: de autoria própria

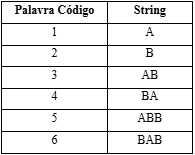
Fonte: de autoria própria

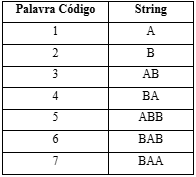
Fonte: de autoria própria

CODIFICAÇÃO HUFFMAN
A codificação Huffman é um algoritmo de compactação de dados sem perdas. A ideia é atribuir códigos de comprimento variável aos caracteres de entrada, os comprimentos dos códigos atribuídos são baseados nas frequências dos caracteres correspondentes.
Os códigos de comprimento variável atribuídos aos caracteres de entrada são chamados códigos de prefixo, o que significa que os códigos (sequências de bits) são atribuídos de uma forma que o código atribuído a um caractere não é o prefixo do código atribuído a qualquer outro caractere. É assim que a codificação de Huffman garante que não haja ambiguidade ao decodificar o fluxo de bits gerado.
Para demonstrar a codificação, serão utilizados quatro caracteres (a, b, c, d), e seus códigos de comprimento variável correspondentes sejam a=00, b=01, c=0 e d=1. Essa codificação leva à ambiguidade porque o código atribuído a “c” é o prefixo dos códigos atribuídos a “a” e “b”. Se o fluxo de bits compactado for “0001”, por exemplo, a saída descompactada pode ser “cccd” ou “ccb” ou “acd” ou “ab”.
Existem basicamente duas partes principais na codificação de Huffman:
O método utilizado para construir o código de prefixo é chamado de codificação Huffman. Este algoritmo constrói uma árvore de baixo para cima usando uma fila de prioridade (ou heap)
ETAPAS PARA CONSTRUIR A ÁRVORE DE HUFFMAN:
A entrada é uma matriz de caracteres únicos, juntamente com sua frequência de ocorrências e a saída é a Árvore de Huffman.
Passo 1: Criar um nó folha para cada caractere exclusivo e crie um “min heap” de todos os nós folha (Min Heap é usado como uma fila de prioridade. O valor do campo de frequência é usado para comparar dois nós no heap mínimo. Inicialmente, o caractere menos frequente está na raiz)
Passo 2: Extrair dois nós com a frequência mínima do heap mínimo.
Passo 3: Criar um novo nó interno com uma frequência igual à soma das frequências dos dois nós. Faça o primeiro nó extraído como seu filho esquerdo e o outro nó extraído como seu filho direito. Adicione esse nó ao min heap.
Passo 4: Repetir as etapas ‘2’ e ‘3’ até que o heap contenha apenas um nó. O nó restante é o nó raiz e a árvore está completa.
Segue a aplicação do algoritmo com um exemplo, dada a tabela abaixo com os caracteres e a frequência de ocorrência deles:
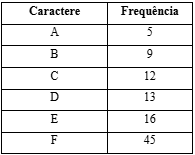
Fonte: de autoria própria
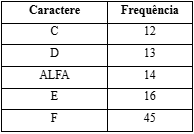
Passo 1: Criar um heap mínimo que contenha 6 nós em que cada nó representa a raiz de uma árvore com um único nó.
Passo 2: Extrair dois nós de menor frequência do heap mínimo. Adicione um novo nó interno (chamado ALFA) com frequência 5 + 9 = 14.
Figura 2 – Ilustração da extração dos dois nós de menor frequência
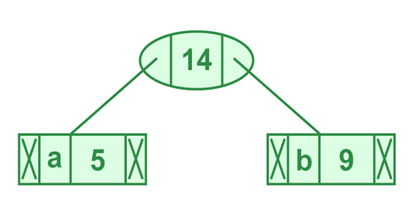
Fonte – Codificação Huffman | Algo-3 ganancioso – GEEKS FOR GEEKS – Disponível em https://www.geeksforgeeks.org/huffman-coding-greedy-algo-3. Acessado em 17 mai 2025
Agora, o heap mínimo contém 5 nós, sendo que 4 nós são raízes de árvores com um único elemento cada (c,d,e,f), e um nó de heap é a raiz da árvore com 3 elementos (ALFA).
Fonte: de autoria própria
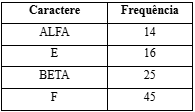
Passo 3: Extrair dois nós de menor frequência do heap. Adicionar um novo nó (chamado BETA) interno com frequência 12 + 13 = 25
Figura 3 – Ilustração da extração dos dois nós de menor frequência
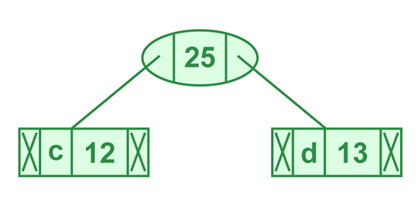
Fonte – Codificação Huffman | Algo-3 ganancioso – GEEKS FOR GEEKS – Disponível em https://www.geeksforgeeks.org/huffman-coding-greedy-algo-3. Acessado em 17 mai 2025
Agora, o heap mínimo contém 4 nós, sendo que 2 nós são raízes de árvores com um único elemento cada (e, f), e dois nós de heap são raiz da árvore com mais de um nó (ALFA, BETA).
Fonte: de autoria própria
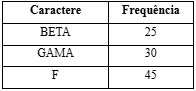
Passo 4: Extrair dois nós de frequência mínima. Adicionar um novo nó interno (chamado GAMA) com frequência 14 + 16 = 30
Figura 4 – Ilustração da extração dos dois nós de frequência mínima
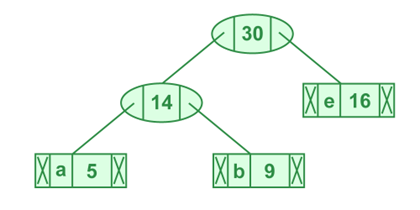
Fonte – Codificação Huffman | Algo-3 ganancioso – GEEKS FOR GEEKS – Disponível em https://www.geeksforgeeks.org/huffman-coding-greedy-algo-3. Acessado em 17 mai 2025
Agora o heap mínimo contém 3 nós (BETA, GAMA, f).
Fonte: de autoria própria
Passo 5: extrair dois nós de frequência mínima. Adicionar um novo nó interno chamado TETA com frequência 25 + 30 = 55
Figura 5 – Ilustração da extração dos dois nós de frequência mínima
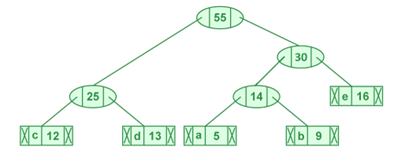
Fonte – Codificação Huffman | Algo-3 ganancioso – GEEKS FOR GEEKS – Disponível em https://www.geeksforgeeks.org/huffman-coding-greedy-algo-3. Acessado em 17 mai 2025
Agora o heap mínimo contém 2 nós.
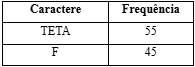
Fonte de autoria própria
Passo 6: Extraia dois nós de frequência mínima. Adicione um novo nó interno com frequência 45 + 55 = 100
Figura 6 – Ilustração da extração dos dois nós de frequência mínima
Fonte – Codificação Huffman | Algo-3 ganancioso – GEEKS FOR GEEKS – Disponível em https://www.geeksforgeeks.org/huffman-coding-greedy-algo-3. Acessado em 17 mai 2025
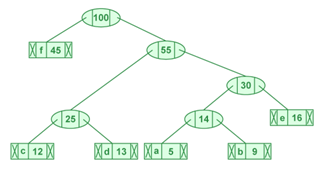
Agora, o heap mínimo contém apenas um nó. Sendo que a frequência de caracteres do nó interno é 100. Como o heap contém apenas um nó, o algoritmo para aqui.
ETAPAS PARA IMPRIMIR CÓDIGOS DA ÁRVORE HUFFMAN:
Atravesse a árvore formada a partir da raiz. Manter uma matriz auxiliar. Ao mover para o filho esquerdo, escreva “0” na matriz. Ao mover para o filho direito, escreva “1” na matriz. Imprima a matriz quando um nó folha for encontrado.
Figura 7 – Árvore de Huffman
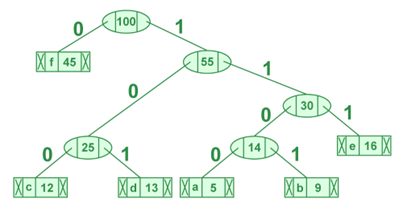
Fonte – Codificação Huffman | Algo-3 ganancioso – GEEKS FOR GEEKS – Disponível em https://www.geeksforgeeks.org/huffman-coding-greedy-algo-3. Acessado em 17 mai 2025
Os códigos que formam os caracteres, seguindo a árvore de Huffman, seguem na tabela abaixo.
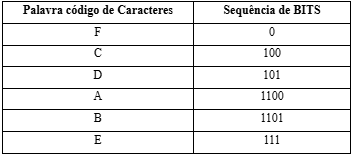
Fonte: de autoria própria
CONSIDERAÇÕES FINAIS
A compactação sem perdas é um método de compactação que torna os arquivos menores sem perder dados. Ele reconstrói perfeitamente os dados originais a partir dos dados compactados.
Quando você precisa de coisas como fotos médicas ou desenhos técnicos, para ser exato, a compactação sem perdas é essencial porque mantém todos os detalhes originais.
A compactação sem perdas remove elementos de imagem duplicados estatísticos dos arquivos de imagem e cria menores. Manter os elementos principais preserva a qualidade da imagem.
Algumas vantagens da compactação sem perdas está em manter a qualidade original, é reversível e possui flexibilidade de edição.
Entre as desvantagens se encontram os tamanhos de arquivo maiores, não é compatível com a WEB (uma vez que podem diminuir o tempo de carregamento do site devido aos seus tamanhos maiores) e a compactação é limitada.
REFERÊNCIAS BIBLIOGRÁFICAS
Algoritmo LZW (Lempel-Ziv-W) – PORTAL Unicamp – Filho, Danilo Zanatta. Disponível em https://www.decom.fee.unicamp.br/dspcom/EE088/Algoritmo_LZW.docvacidade. Acessado em 02 mai 2025
Fileformat.Blogs – Algoritmos de compressão sem perdas –. Disponível em https://blog.fileformat.com/pt/compression/lossy-and-lossless-compression-algorithms/. Acesso em: 25 abr. 2025.
GEEKS FOR GEEKS – Codificação Huffman | Algo-3 ganancioso – Disponível em https://www.geeksforgeeks.org/huffman-coding-greedy-algo-3. Acessado em 17 mai 2025
SALOMON, David (2000). Data Compression. The Complete Reference 2 ed. Nova Iorque: Springer. ISBN 0-387-95045-1
The Scientist and Engineer’s Guide to Digital Signal Processing By Steven W. Smith, Ph.D. Disponível em LZWhttps://www.dspguide.com/ch27/5.htm Compression. Acesso em 25 abr. 2025
TechTudo. – Saiba o que é codec para se dar bem com qualquer arquivo de áudio e vídeo – Disponível em https://www.techtudo.com.br/noticias/2012/10/saiba-o-que-e-codec-para-se-dar-bem-com-qualquer-arquivo-de-audio-e-video.ghtml. Acesso em: 25 abr. 2025.
WsCube Tech. – Algoritmos comuns de compactação sem perdas – Disponível em https://www.wscubetech.com/resources/dsa/compression-algorithms. Acesso em 15 abr. 2025








